
Disclaimer: I wrote this post about six weeks ago but forgot to publish it, I probably should start using scheduling. Hope you enjoy it anyway!…
Tag: continuous delivery

When you write software, you can end up in a place where your continuous integration takes too long to execute. For most of the post I will write CI because it’s faster to type. Also it makes your read slightly faster.
When delivering software continuously, the more complex solution, the more you are prone to having a slow CI process at some point. Note that a limited computing power also increases the chances of slow CI becoming your burden.
Here, get some context
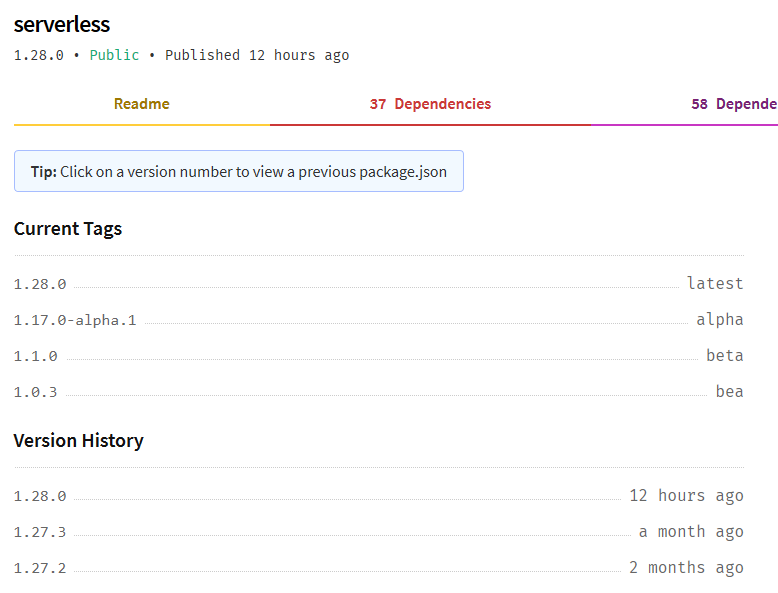
Hey everyone, let me tell you about Serverless‘ latest release. You must be thinking “Three posts in ten days after three months absence what got into you JD?”. Nothing particular, well now that I go exercise in the morning and finish work around 5 I have tons of time to do stuff afterwards. Also I keep running into things from that feel blog worty. Indeed, today I experienced what can easily become a nightmare for developers. Broken continuous integration from out of nowhere. Indeed, this morning as I was making the latest adjustments to a project set to move towards production in a few days, the continuous integration broke after merging my latest pull request. The pull request contained minor changes in a configuration but nothing that would be used at any point through CI.

Continuous delivery for free using Docker, CircleCI and Heroku
Posted in .NET Core, Building future-proof software, and Tutorials
Continuous what?
Continuous delivery. You may recall that in my previous post I announced that today’s entry would be revolving around continuous integration. And technically it can count as such since we will cover continuous integration along the next step. That next step is continuous delivery. If you are not familiar with these terms and the concepts behind them I will sum them up briefly.
Basically, continuous integration allows verifying that your codebase still builds and passes tests passing whenever you push changes. Add a trigger to deploy your code to production upon success and you pretty much have the idea around continuous delivery.