
Hello everybody, here we are. The day that I finally tackle CloudFormation. As far as I can remember I always told myself. Even though I…
Tag: aws

I remember back in September when I decided to write this post. A post about building a simple Go app to then deploy it to…

On August 20th after a chat with my lead, I decided to practice to take on the AWS Solutions Architect Associate exam. I spent the…

How did that even come up?
I originally started writing another post last week but in the meantime I did a domain name migration. What is a domain name migration you will ask? It is the act of migrating content from a domain to another domain. Not host, domain. If this was about host migration there would be no need for a post as the changes would be straightforward. People may give you a different or more precise description but it is basically what I did. And also what it sounds like. I like to name things so that when they are described or revealed they turn out to be pretty much what you expect. It’s like coding. If I have a piece of code with a method boolean validatePassword(string username, string password) when looking at the code you pretty much expect to see some user retrieval and maybe encoded password validation. You definitely do not expect a session to be started or anything funny like that. Enough with this, let’s get back onto today’s topic. Domain name migration.
Here, get some context
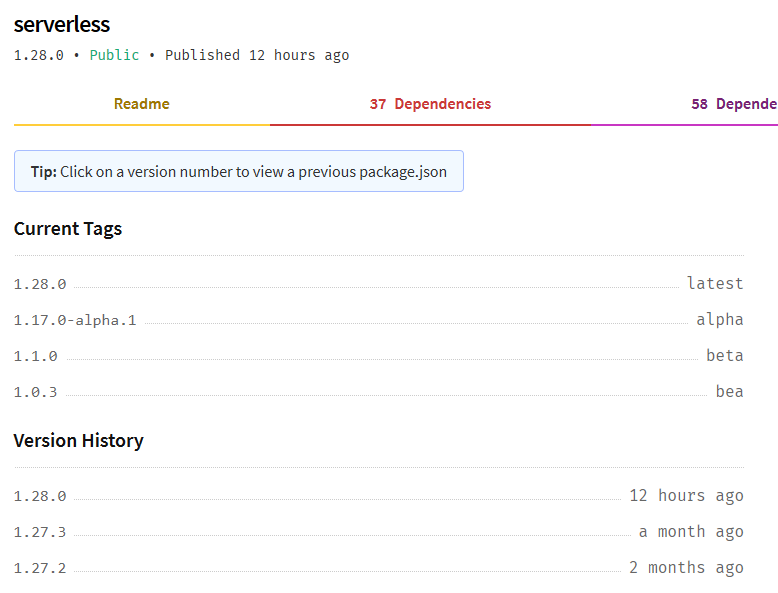
Hey everyone, let me tell you about Serverless‘ latest release. You must be thinking “Three posts in ten days after three months absence what got into you JD?”. Nothing particular, well now that I go exercise in the morning and finish work around 5 I have tons of time to do stuff afterwards. Also I keep running into things from that feel blog worty. Indeed, today I experienced what can easily become a nightmare for developers. Broken continuous integration from out of nowhere. Indeed, this morning as I was making the latest adjustments to a project set to move towards production in a few days, the continuous integration broke after merging my latest pull request. The pull request contained minor changes in a configuration but nothing that would be used at any point through CI.